iOS 启动优化方案
28 Mar 2021 | iOS介绍
iOS 启动优化非常重要, App 是否能够留存用户, 用户使用体验是否良好, 启动速度占的很大因素
本篇目录
查看 pre-main 阶段耗时
main函数启动前的阶段也叫 pre-main
Xcode提供了查看pre-main阶段耗时的工具
点出 Edit Scheme -> Run -> Auguments 添加环境变量, 其实 Value 值可以不填, 对需要使用的变量要打钩, 其中:
DYLD_PRINT_STATISTICS打印耗时信息DYLD_PRINT_STATISTICS_DETAILS打印耗时的详细信息
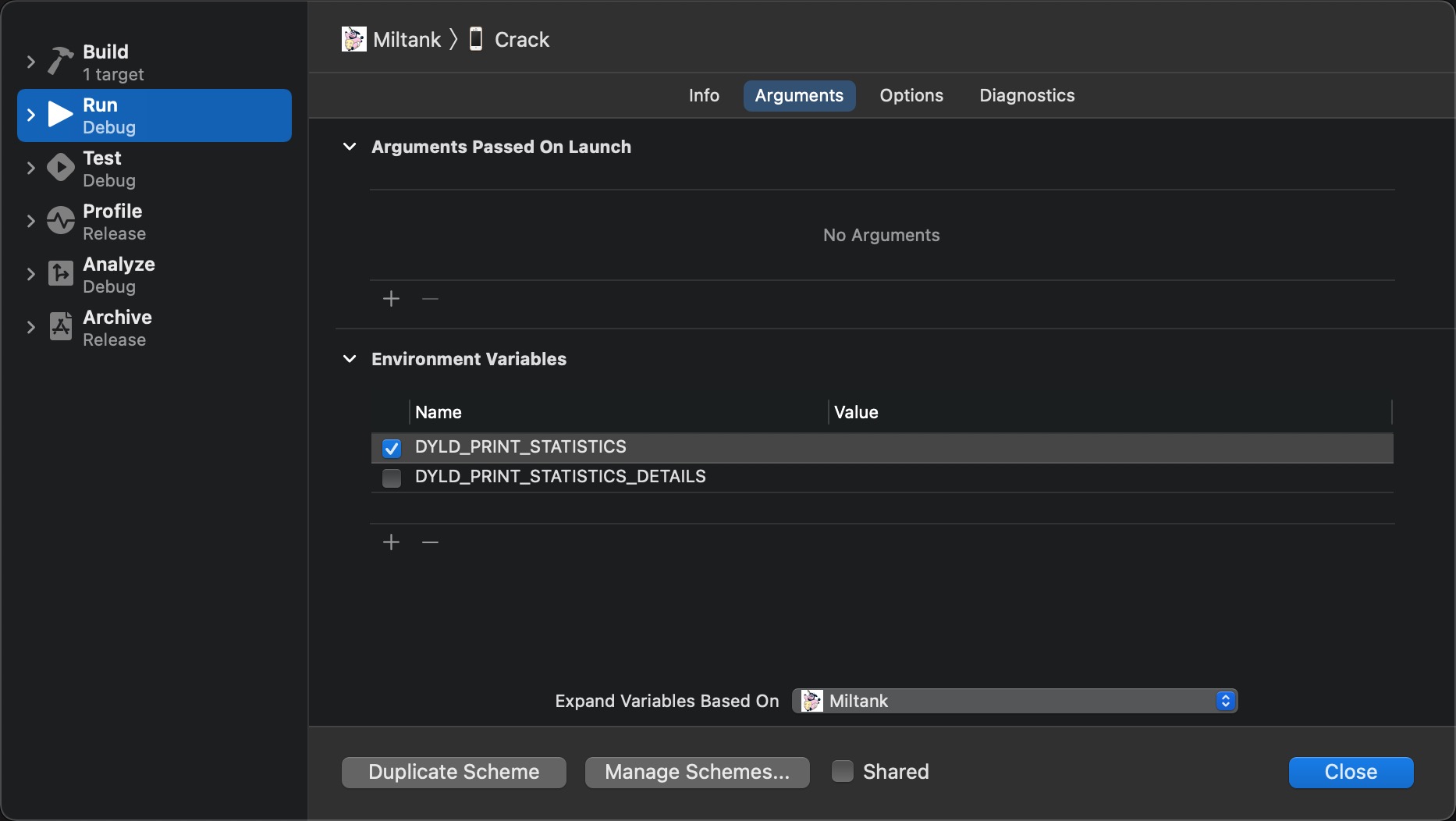
得到类似以下输出
Total pre-main time: 328.10 milliseconds (100.0%)
dylib loading time: 139.24 milliseconds (42.4%)
rebase/binding time: 19.44 milliseconds (5.9%)
ObjC setup time: 17.21 milliseconds (5.2%)
initializer time: 152.19 milliseconds (46.3%)
slowest intializers :
libSystem.B.dylib : 3.31 milliseconds (1.0%)
libBacktraceRecording.dylib : 6.85 milliseconds (2.0%)
libMainThreadChecker.dylib : 43.23 milliseconds (13.1%)
Miltank : 164.07 milliseconds (50.0%)
pre-main 阶段
pre-main部分大概分为两个阶段,dyld和runtime两部分
- [dyld 部分] load dylibs**: 找到
dylib对应的Mach-O文件 - [dyld 部分] rebase: 修复的是指向当前镜像内部的资源指针(
Mach-O加载到内存后, 地址是存在偏移的, 详见ASLR) - [dyld 部分] binding: 就是将这个二进制调用的外部符号进行绑定的过程, 比如我们
Objective-C代码中需要使用到NSObject, 即符号OBJC_CLASS$_NSObject, 但是这个符号又不在我们的二进制中, 在系统库Foundation.framework中, 因此就需要binding这个操作将对应关系绑定到一起 - [runtime 部分] objc: 运行时的初始处理, 包括
Objective-C相关类的注册,Category注册,Selector唯一性检查等 - [runtime 部分] initializers: 包括了执行
+load()方法,attribute((constructor))修饰的函数的调用, 创建C++静态全局变量
pre-main 优化建议
- 减少动态库数量, 能合并的动态库尽量合并, 移除掉不使用的库, 苹果建议最多使用 6 个非系统的动态库
- 减少加载启动后不会去使用的类, 分类, 方法
- 尽量不使用
+load()方法, 在一个+load()方法里, runtime 方法替换操作会耗时 4 ms, 大约 2000 个类需要耗时 800ms, 推荐 +initialize() 和 dispatch_once 方法同时使用来替换 - 尽量控制 C++ 全局变量, C++静态构造器代码
// 使用 initialize + dispatch_once 的组合
+ (void)initialize {
// 使用 once 是因为 initialize 可能会被调用多次
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
// 在这里做替代 load 的事情
});
}
main 函数执行后的阶段
main阶段主要是从main()开始到didFinishLaunchingWithOptions方法结束, 首屏渲染会在这其中完成
main优化分为两个部分, 一个首屏渲染前和首屏渲染后
为什么要区分首屏渲染前和首屏渲染后, 是因为我们可以在didFinishLaunchingWithOptions还在执行的时候就尽快让用户看到页面, 不必等待和首屏渲染无关的代码执行完了之后才渲染, 没有意义并且影响体验
业务级别优化
一般情况下, 项目经过长久的迭代之后, didFinishLaunchingWithOptions方法里面堆积了很多业务代码, 类库初始化代码
根据业务, 对相应的代码进行梳理, 有哪些是可以不需要在当前方法里执行的, 有哪些是需要的, 但是不需要在首屏渲染前做的
针对首屏渲染前优化建议
一切的目的就是为了尽快让用户先看到页面, 所有为了首屏渲染的, 都是最高优先级
- 首屏渲染需要初始化的类
- 首屏渲染需要的数据
针对首屏渲染后优化建议
现在用户已经看到了页面, 后面的逻辑处理可以宽松一点了
- 执行其他业务的初始化, 一些监听注册的内容
didFinishLaunchingWithOptions方法里面, 注意不要执行过于耗时的操作, 导致用户看到首页后, 但是页面交互卡顿- 必需的类/方法延后执行, 按需加载
方法级别优化
我们已经对main函数进行了业务梳理, 能做到上面的内容, 应用已经有比较明显的速度提升, 但是这还不能满足对于更进一步的速度提升, 需要更加细化的操作
应用运行期间, 我们需要获取到在某个阶段, 所有方法调用的耗时, 以便分析
Time Profile 查看耗时
官方Instruments自带的Time Profile已经是做的比较精细的工具了, 通过录制的数据可以查看所有的阶段的耗时信息
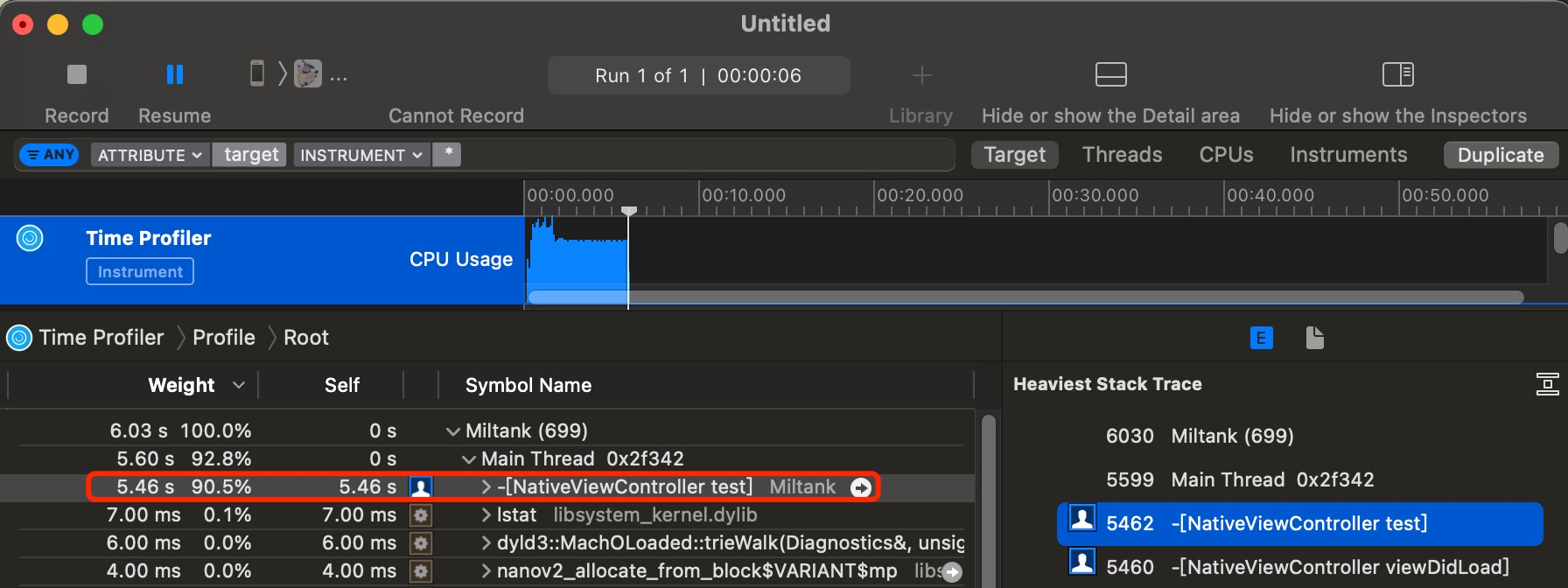
在通用性上, Time Profile一定是最好的耗时统计工具, 支持多维度 UI 查看, 多线程堆栈数据, 自定义选取时间节点等功能, 但也有他的缺点,
因为Time Profile是定时采样的, 时间间隔太短, 导致无意义的性能消耗, 时间间隔如果太长, 会导致有些方法会被错过
采样时间间隔太长太短都不好, 如果对时间耗费有更精确的需求, 那应该考虑下面自定义的方法
hook 方式得到耗时
看到两个比较典型的实现:
- 动态hook,
fishhook+objc_msgSend进行运行时hook - 静态替换, 修改静态库文件的方法符号, 调用主工程的
hook_method
动态 hook 社区实现
Objective-C中每个对象的isa指针都会指向类/元类, 每个类/原类都会有一个方法列表, 方法列表里的每个方法都是由 SEL(选择器), IMP(函数指针)
所以只要hookobjc_msgSend方法, 就可以hook全部Objective-C的方法
@戴铭的GCDFetchFeed: 采用 fishhook + objc_msgSend, 打印信息可以直观看到方法的调用层级和耗时
// 在检测耗时开始的地方调用 start
[SMCallTrace start];
// 这中间是需要检测的代码
// 结束时调用 stop save
[SMCallTrace stop];
[SMCallTrace save];
输出如下:
--smcall-- 0| 5.30|-[SMRootViewController setTitle:]
--smcall-- path[SMRootViewController setTitle:]
--smcall-- 0| 58.72|-[SMRootViewController tableView]
--smcall-- path[SMRootViewController tableView]
--smcall-- 0| 1.43|-[NSKVONotifying_UITableView mas_makeConstraints:]
--smcall-- path[NSKVONotifying_UITableView mas_makeConstraints:]
--smcall-- 0| 1.27|-[SMDB selectAllFeeds]
--smcall-- path[SMDB selectAllFeeds]
--smcall-- 0| 13.54|-[RACSubscriptingAssignmentTrampoline setObject:forKeyedSubscript:]
--smcall-- path[RACSubscriptingAssignmentTrampoline setObject:forKeyedSubscript:]
--smcall-- 0| 10.25|-[RACDynamicSignal subscribeNext:]
--smcall-- path[RACDynamicSignal subscribeNext:]
静态替换
@maniac_kk的KKMagicHook
主要实现思路是把想要检测的代码编译成静态库, 在静态库链接之前, 修改静态库中的字符串表部分, 将字符串表中的objc_msgSend字符串替换为hook_msgSend字符串,
其中hook_msgSend是自己实现的hook方法
二进制重排方案
二进制重排方案的侧重点, 是在于减少启动时的缺页异常Page Fault从而减少启动时间
关于二进制重排的具体原理, 抖音的文章已经讲得非常细节
抖音研发实践:基于二进制文件重排的解决方案 APP启动速度提升超15%
System Trace 查看耗时
Page Fault发生的时候, 线程信息无法查看, 这时候就需要System Trace,
System Trace在Time Profile不够用的时候使用, 它可以更加全面看到CPU线程调度情况, 查看系统调用和虚拟内存的Fault
搜索主线程, 在
选中主线程, 在下方的Main Thread面板选中Summary: Virtual Memory, 显示的File Backed Page In的Count就是Page Fault次数, 点击能看到Page Fault时的堆栈信息
虚拟内存
进程如果能直接访问物理内存无疑是很不安全的, 所以操作系统在物理内存的上又建立了一层虚拟内存. 为了提高效率和方便管理, 又对虚拟内存和物理内存又进行分页(
Page). 当进程访问一个虚拟内存Page而对应的物理内存却不存在时, 会触发一次缺页中断Page Fault,分配物理内存, 有需要的话会从磁盘mmap读人数据
通过App Store渠道分发的App,Page Fault还会进行签名验证, 所以一次Page Fault的耗时比想象的要多
Link Map File
Link Map File是在源码编译的阶段, 用来记录目标文件链接映射文件, 里面记录了所有的源码内容, 方法, 类, block, 偏移位置以及大小
链接文件可以通过修改Build Settings -> Write Link Map File 值为YES 得到
查看Link Map File的结构, 发现文件的顺序和 Build Phases -> Compile Sources 的文件顺序是一致的, 类内的方法实现靠前, 文件内的符号也会靠前
在链接文件里面, 如果把相关方法都集中放到一起, 那么就更加容易被mmap到同一页内存表里, 现在问题就变成, 找到一个修改链接文件里面的方法顺序的方法
PS: 因为Link Map File记录所有的占用内存大小信息, 也记录了所有的方法调用, 用来给安装包瘦身是一个很好的选择
Order File
Xcode使用ld作为链接器, ld有一个参数-order_file, 可以接收一个order file来指定链接的时候, 方法符号的优先级, order file的优先级就是ld链接时候的优先级
Xcode也提供了Order File的设置选项: Build Settings -> Linking -> Order File, 在里面设置./yourfile.order
文件有自己的格式, 内容示例如下:
_main
-[AppDelegate window]
-[AppDelegate setWindow:]
-[AppDelegate application:didFinishLaunchingWithOptions:]
_$s19AppOrderFilesSample0A9SwiftTestC3fooyyFZTo
_$s19AppOrderFilesSample0A9SwiftTestC3fooyyFZ
_$ss5print_9separator10terminatoryypd_S2StFfA0_
_$ss5print_9separator10terminatoryypd_S2StFfA1_
基于 Clang 代码插桩
Clang SanitizerCoverage是LLVM提供的代码覆盖工具, 定义如下:
LLVM has a simple code coverage instrumentation built in (SanitizerCoverage). It inserts calls to user-defined functions on function-, basic-block-, and edge- levels. Default implementations of those callbacks are provided and implement simple coverage reporting and visualization, however if you need just coverage visualization you may want to use SourceBasedCodeCoverage instead.
它可以把__sanitizer_cov_trace_pc_函数插入到每一个写好的方法里面, 因为支持覆盖Objective-C/C/C++/Swift, 也支持 Block,
这种方案就可以弥补fishhook hook objc_msgSend这个方案无法覆盖到的盲区: block函数, load方法, initialize, C/C++
在二进制重排里面, 只需要使用function levels这个桩, 在Xcode里面开启配置:
Build Settings -> Custom Complier Flags -> Other C Flags值加入
-fsanitize-coverage=func,trace-pc-guard
如果需要覆盖 Swift,
Build Settings -> Custom Flags -> Other Swift Flags 值加入
-sanitize-coverage=func 和
-sanitize=undefined
Github上已经有人做了关键实现AppOrderFiles, 核心思路是
每次方法在调用的是, 都会触发__sanitizer_cov_trace_pc_guard方法, 用一个结构体链表顺序存储方法地址信息, 为了保证在多线程环境下采集数据安全,
又起了一个原子队列. 触发队列出队拿出数据, 使用dladdr查询地址所在的符号信息, 去重后把方法名String存在自定义的 order file 里面
static OSQueueHead queue = OS_ATOMIC_QUEUE_INIT;
static BOOL collectFinished = NO;
typedef struct {
void *pc;
void *next;
} PCNode;
// The guards are [start, stop).
// This function will be called at least once per DSO and may be called
// more than once with the same values of start/stop.
void __sanitizer_cov_trace_pc_guard_init(uint32_t *start,
uint32_t *stop) {
static uint32_t N; // Counter for the guards.
if (start == stop || *start) return; // Initialize only once.
printf("INIT: %p %p\n", start, stop);
for (uint32_t *x = start; x < stop; x++)
*x = ++N; // Guards should start from 1.
}
// This callback is inserted by the compiler on every edge in the
// control flow (some optimizations apply).
// Typically, the compiler will emit the code like this:
// if(*guard)
// __sanitizer_cov_trace_pc_guard(guard);
// But for large functions it will emit a simple call:
// __sanitizer_cov_trace_pc_guard(guard);
void __sanitizer_cov_trace_pc_guard(uint32_t *guard) {
if (!*guard) return; // Duplicate the guard check.
if (collectFinished) {
return;
}
// If you set *guard to 0 this code will not be called again for this edge.
// Now you can get the PC and do whatever you want:
// store it somewhere or symbolize it and print right away.
// The values of `*guard` are as you set them in
// __sanitizer_cov_trace_pc_guard_init and so you can make them consecutive
// and use them to dereference an array or a bit vector.
*guard = 0;
void *PC = __builtin_return_address(0);
PCNode *node = malloc(sizeof(PCNode));
*node = (PCNode){PC, NULL};
OSAtomicEnqueue(&queue, node, offsetof(PCNode, next));
}
One More Thing
上面的复杂操作, 是可以封装抽象的, 封装后只要一行代码就能做到
AppOrderFiles(^(NSString *orderFilePath) {
NSLog(@"OrderFilePath:%@", orderFilePath);
});
总结
- 业务逻辑梳理带来的启动速度的收益是占大头的
- 优化是一个继续的过程, 优化完成之后, 守住成果不腐化, 也是需要一系列方法的
- 获取符号和
hook方法各有优劣, 依照场景使用对应方案 - 使用
Clang的插桩也不是万能的, 有些使用静态库也不会重新编译, 是不能覆盖到的 - 二进制重排不是启动优化优先应该考虑的方案
iOS13的dyld的加载已经改了优化方式, 二进制重排的方案的优化效果会有所减少
Comments